我认为,2023 年将会是人工智能界有史以来最激动人心的一年。我是真心认为 2022 年是我们经历过的最激动人心的一年之后说出这番话的。创新的步伐不断加快。
这就是“万事都有副驾驶”的梦想——无论你从事什么样的认知工作,你身边都会有一位副驾驶,不但能帮你做很多事情,还能以新的、令人兴奋的方式提高你的创造力。
以前的每个产品都需要一个专门的模型来处理。现在你有一个单一的模型,可以在很多地方使用,因为它们有广泛的用途。能够投资于这些随着规模扩大而变得更加强大的模型,然后在模型之上构建所有的东西,同时从您正在进行的改进中受益——这是非常了不起的。其中一些进展是通过使用越来越大的 GPU 集群来实现蛮力计算规模。但也许更大的突破是软件层,它优化了模型和数据在这些巨大系统中的分布方式,既可以训练模型,也可以为客户提供服务。如果我们要把这些大型模型作为人们可以创造的平台,它们就不能只被世界上极少数拥有足够资源来建造巨型超级计算机的科技公司所利用。
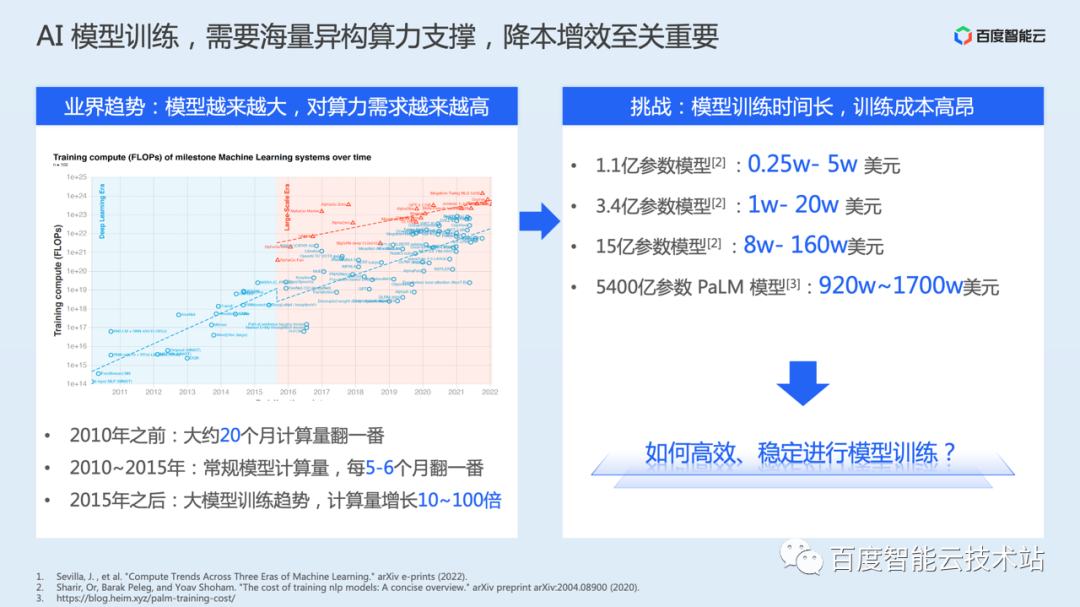
提到 Google 5400 億參數的 PaLM 語言模型 (Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance),其訓練成本超過 1000 萬美元。
結合
- 新創 OpenAI 公司 (及背後的支持者微軟) 以預覽方式公開大眾使用模型
- 超大型通用語言模型可輕鬆打敗專屬領域之語言模型
- 僅有少數超大型公司能負擔這樣的訓練成本
- 從正在進行的改進中受益
- 摩爾定律正逐漸走向盡頭 (摩爾定律還沒走到盡頭?盤點半導體未來的三大挑戰) (新的 GPU 體積越來越大越耗電,而不是相同體積功耗下每兩年容量效能翻倍)
這五點,我大膽往下推測:
- 過去大公司為了避免形象受損,較少積極公開成果,今後會在競爭加劇的環境中,更積極推出成果,但相對也會較少考慮模型造成之負面問題
- 大家趨向於先追求進步,再來談防護,導致防護持續落後於進步
- 超大型通用模型 (不僅僅是語言) 取代專屬模型
- 專屬模型背後的組織/公司無法負擔從頭開發訓練的人才及成本,基本上只能找最好的公開模型 (在吃得下的大小範圍內),再加以遷移學習以適用自己的需要 (下一個新的模型公開,自己的硬體再提升後,再重新遷移學習一次)
- 超大型通用模型只有超大型公司自己能持續改善,利益當然也是獨佔
- 連國家級機構也無法跟上超大型公司的進步腳步
- AI 進步速度受後摩爾時代限制,無法自然地指數成長
- 通用人工智慧仍需理論上的重大突破
- 哪一個公司最快達成通用人工智慧,將具有巨大優勢,將所有人/公司/國家遠遠拋在腦後
- 何時能達成通用人工智慧還不得而知,但工作機會減少,虛假訊息增加,善用 AI 的人勝過守舊的人等等,會先影響世界局勢,更加動盪不安
至於實體機器人的話,我認為發展會慢得多。因為純軟體自我訓練非常快,訓練完直接上雲端,就可以極低成本提供服務給全世界百萬人使用。
而實體機器人,就拿已經開發出來的機器狗來說好了,一台賣多少錢? 全世界賣了幾台? 我沒去查數據,可想而知一定相當貴,銷量很少。而要開發下一代,除了必須要有實體世界的虛擬建模,先純軟體虛擬訓練後,再開發對應的初版機器。初版機器相信也要操壞撞壞不少台,不斷再改善修正,最後才能少量量產來賣。可想而知硬體的迭代速度慢得多,成本高得多。
我相信智慧機器人還是在工廠/倉儲這類高度受控環境 (出問題不會被挑剔客戶告),又花得起錢的地方比較有賣點。一般人要享用,還早得很。
雖然大型工廠的自動化生產已經很厲害了,但多是過去非 AI 技術就能做到的程度。以深度學習方式訓練的機器人,其進展速度仍然比不上純軟體的服務。
眼下進展最快的,應該還是自駕車了。但碰到法律、生命,甚至道德問題,還是困難重重,喊了多少年,進度並不快。像 ChatGPT 有多少虛假訊息,有看哪一國跳出來說不可以,一定要限制要嚴懲嗎? 但自駕車在各國都嚴加把關,不容生命財產損失。
因此我認為純資訊/知識性的 AI 軟體/服務,發展會非常快,牽涉到硬體的就慢得多。照著推論下來,知識性工作被取代的速度,將有可能比實體作業性工作被取代的速度還快。而工廠作業員被取代的速度,又比直接面對普羅大眾的實體工作更快。若牽涉到法律、政治、醫學方面,又還要更慢。
腦機介面? 真的還要更遠更遠以後,我推測會在通用人工智慧之後了。那時還是人來控制電腦,還是由電腦控制人了?
